“Agent.md & Skill.md: Why current practice is costing us tokens, safety, and sanity”

TL;DR
- Agent and skill frontmatter is inconsistent across agent runtimes. That ambiguity causes brittle discovery, fragile installs, wasted tokens, and supply‑chain risk.
- I show a small, reproducible experiment (OpenClaw blogwatcher + Docker cagent) that exposes these frictions.
- In a future post, I will provide a versioned schema, define specification compliance tiers, provide a schema validator, and migration tooling to fix this.
A Simple SKILLS.md and Agent.md Migration Experiment
I grabbed the blogwatcher skill from OpenClaw, dropped it into ~/.agents/skills, and tried to use Docker’s cagent to run an agent that invoked the skill. The skill didn’t show up in cagent’s TUI. After removing almost all frontmatter from SKILL.md except the name and description, the skill appeared and worked.
That tiny manual edit should not have been the make-or-break step. It revealed three realities: frontmatter is overloaded with tool and agent-specific metadata; discovery semantics vary between agent runtimes; and small differences in metadata can cause usability problems. The result is brittle workflows, surprised users, and — importantly — unnecessary token consumption and security exposure
At first glance, this looks like a implementation gap you can fix with guidance text in a agent.md or skill.md file. It isn’t. The current practice has three aspects:
- Cost (token spend): Poorly structured skill/agent interactions increase the number and verbosity of LLM calls. Repeated agent-to-LLM interactions, long instructions, and ambiguous tool-call semantics translate directly into tokens and dollars.
- Safety and supply chain: Automatic installs with no checksums, signatures, or well-defined lifecycle are a potential operational risk.
- Developer experience and reproducibility: Teams must know exactly how agent runtimes discover and index skills. When discovery rules differ, CI, local dev, and production diverge, making deployments brittle.
The current coding doctrine that we all need to be writing Agent.md and SKILL.md files has me wondering how are we to manage, discover, package and distribute these files. As much I want to believe that writing software begins with writing Agents.md and SKILL.md files, I remain skeptical. And, have been crawling through Openclaw and pi-mono code to gain insight into how they consume agents and skill files. And studying the Agents Skills specification in search of an answer.
Going into the experiment my focus was on the frontmatter that pi-mono and Openclaw require in the SKILL.md file. The Openclaw frontmatter is shown below. It leverages the metadata property to define the installation dependencies for a skill. The handling of the metadata is Openclaw specific and not within the scope of the Agents Skill specification.
---
name: blogwatcher
description: Monitor blogs and RSS/Atom feeds for updates using the blogwatcher CLI.
homepage: https://github.com/Hyaxia/blogwatcher
metadata:
{
"openclaw":
{
"emoji": "📰",
"requires": { "bins": ["blogwatcher"] },
"install":
[
{
"id": "go",
"kind": "go",
"module": "github.com/Hyaxia/blogwatcher/cmd/blogwatcher@latest",
"bins": ["blogwatcher"],
"label": "Install blogwatcher (go)",
},
],
},
}
---As I have mentioned in other posts, I am drawn to Docker's multiple AI initiatives to ease the management of agents and MCP servers. I wrote a simple cagent that invokes the blogwatcher skill:
agents:
root:
model: mistral/mistral-small
instruction: |
You monitor a select list of user-provided blogging sites (provided as URL's) for new postings. Refer to the blogwatcher skill
for additional capabilities.
skills: true
toolsets:
- type: filesystem
- type: shellThe blogwatcher skill was downloaded from openclaw repository as-is. I placed it in my ~/.agents/skills directory and the project folder under .agents/skills. Then launched cagent:
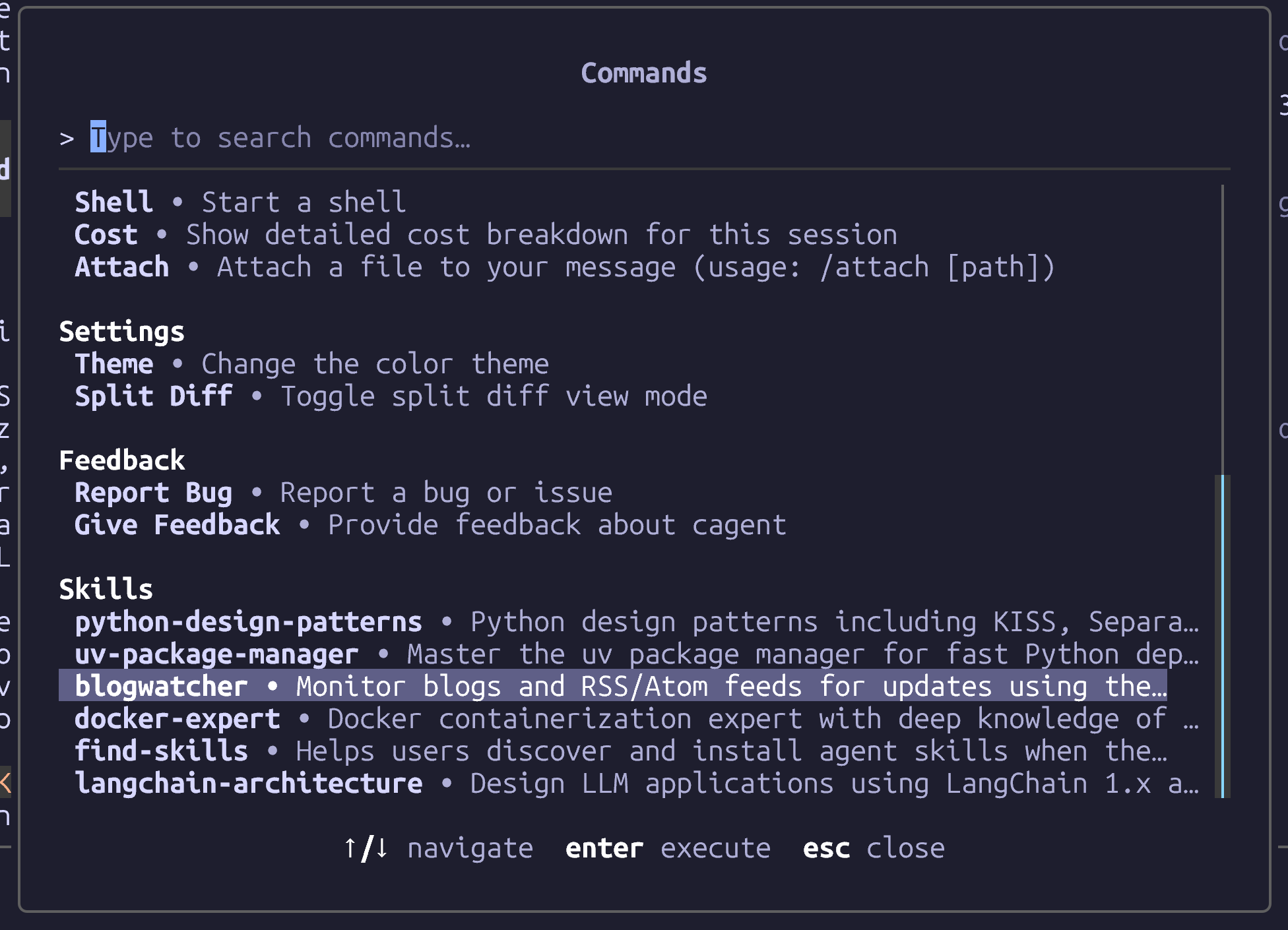
cagent run blogwatcher.yamlThe cagent TUI listed all discovered skills in the Settings section (Ctrl-k). Use the down-arrow to scroll past the Settings:
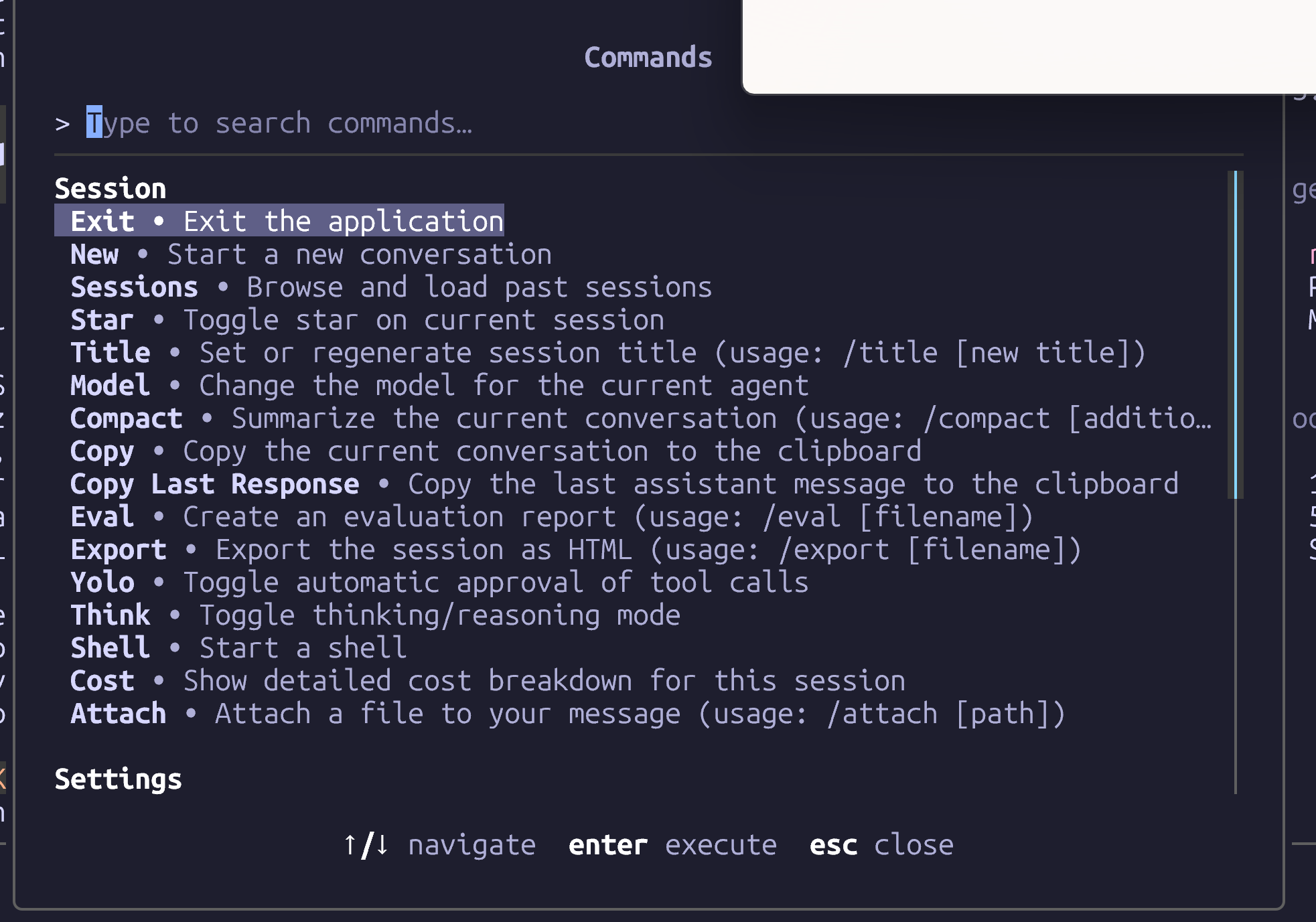
Docker cagent only displayed blogwatcher after removing all the openclaw metadata and only listed the blogwatcher instance copied to ~/.agents/skill. It was blind to the copy stored in the project directory.
When I invoke pi and list the discovered skills the output is as follows:
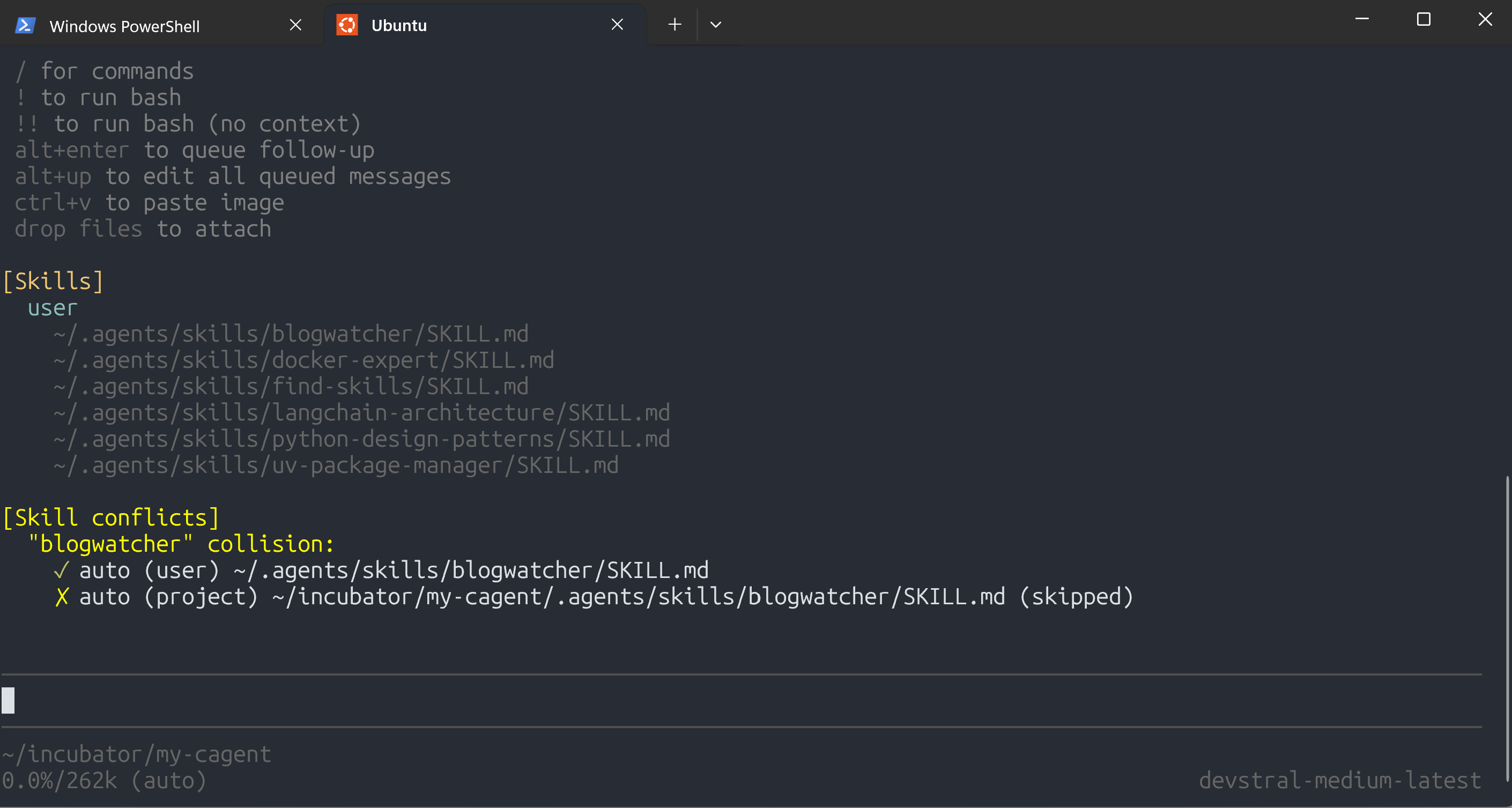
It discovered the multiple copies.
When I first started experimenting with agents and skills, I imagined a simple, portable set of agent.md and skill.md artifacts—that you could drop into any runtime and expect to work. In practice, that portability does not seem to exist. As a result, what should be a straightforward authoring experience becomes a patchwork of runtime-specific tweaks and brittle assumptions.
I propose adopting a progressively-loading agent and skills file model: skill files should be discoverable and loadable on demand, and the specification should support optional, machine-readable dependency declarations that let agent runtimes fetch or enable required packages safely and predictably. The current specification’s advice to keep reference files small—complete with line-count recommendations—points in the right direction, but it feels prescriptive rather than extensible.
A more flexible approach would allow richer frontmatter: optional, feature-based metadata that can be incrementally adopted. Imagine frontmatter fields for capability declarations, dependency manifests, trigger hints, and provenance information. This lets simple authoring stay simple while offering a growth path for authors and agent runtimes where token efficiency and stable reproducibility are critical.
Around the time I drafted these thoughts, the Linux Foundation launched the AGNTCY collaborative to tackle a subset of these issues. If different agent runtimes and vendors converge on a shared vocabulary for agent and skill descriptors, authors gain portability and users gain predictable behavior. AGNTCY appears aimed at enabling interconnection between larger, coordinated “super-agents” — systems that require federation — rather than merely standardizing locally hosted agents and isolated skill plug-ins.
My hope is that the existing agent/skill specification evolves along three lines. First, standardize a core, minimal set of fields that ensure basic portability—name, version, simple capability tags, and a interface that every agent runtime can implement. Second, define an optional extension mechanism (the richer frontmatter) for dependency manifests, capability declarations, and runtime hints so that adopters can scale agent and skill discovery without breaking agent runtimes. Third, bake in guidance for security and provenance—signing, capability scoping, and trusted sources—so that auto-installation and runtime actions do not become security issues.
These changes would shift the specification from a static set of editorial recommendations to a living, layered design: a small, universally-implemented core for immediate portability, plus optional extensions for progressive loading, dependency management, and cross-agent runtime support.
The vision is to enable agent creators to iterate unburdened : authors can keep writing simple, portable agent.md and skill.md files today, and gradually adopt richer frontmatter when they want progressive loading, seamless dependency handling and a consistent multi-vendor agent runtime experience.
I will propose a set of agent and skills schema and extensions to address these points in a forthcoming blog.